
Transcript: All Roads Lead to Infrastructure Automation













The Evolution of Enterprise Storage Management
Eduardo Rivera: We are going to talk today about infrastructure automation, and we’re really going to talk about it within the context of essentially the storage perspective: what does it mean for our enterprise storage management? Thus, you see the title of the presentation is the Evolution of Enterprise Storage Management.
Just as a matter of reintroducing myself, as you said, my name is Eduardo Rivera. I work at NetApp IT, and within NetApp IT I manage what we call the Customer-1. The long name is Customer-1 Solutions Group. Yes, we are the storage team, but we’re also the team that are managing and deploying all sorts of NetApp technology internal to NetApp IT to manage our business. Today’s topic is something that is fairly popular these days, and I find myself talking to a lot of customers about it. We’ve done many different types of interactions around this topic and related items. It’s something that within NetApp IT we have gone through, or I guess I would say we’re going through over the past years, and it’s affecting a lot of our enterprise customers.
What I’m talking about is really the evolution or the evolv
ing trends within storage management with regards to automation and modernization of the enterprise. My intent today is to share with you our NetApp IT experience and perspective. As I go through this presentation, I want the folks in the call to really think about their customers, the environments that they work with, and try to see how their customers and their environments are thinking about these changes, how the changes are manifesting in those environments, and perhaps what stage through that journey those customers are sitting, and how we can help them get through them.
To a large degree, maybe you can draw some similarities between what you have observed and what we’re talking about today in NetApp IT. By the end of the presentation, I want you to walk away with a perspective of what it takes, or what has taken us at least to transform. Again, it’s always a work in progress, to transform into a more modern enterprise automation storage management and infrastructure team, which is what we did today. Now, as Lady said, please, you can throw your questions in the chat as we go through this. I’ll even encourage to speak up if you have a question. I don’t have a ton of slides. I’ll be happy to take my time and talk about particular items, but please, the more interactive we can make it, the better for me. All right. Leyddy and D, if you guys see any questions, also interrupt me and let me know.
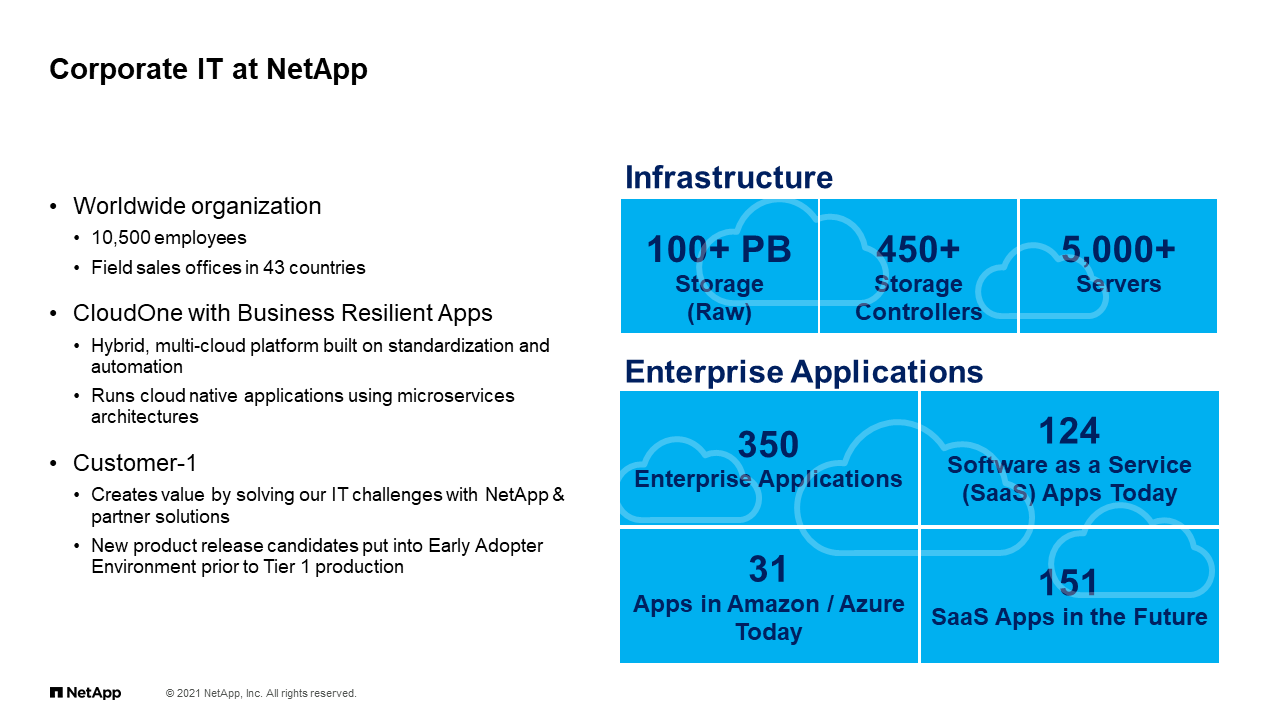
Corporate IT at NetApp
As a general view, and you may have seen a slide like this before in other presentations we’ve done, but I like to put it here for perspective. We are the corporate NetApp IT team. We manage infrastructure for what we call the enterprise side, so everything that has to do with corporate applications that you may use to do your day-to-day job, everything from the Microsoft 365 that you use, to QuoteEdge, to ERP, all those applications that are around the business, we run the infrastructure behind that to make those work. That is across multiple data centers, across multiple world sites, large footprint of storage, compute, networking, both on-prem, off-prem, and also everything in between. All the things are connected.
Because we are in that position, that’s why we call ourselves Customer-1 because we’re the first consumer of all this technology that NetApp creates. We do it on purpose, but the purpose of A, running the business, but B also being a frame of reference for customers or the product team so we can product back feedback of what works, what doesn’t work, experience, et cetera. We play a big role also on this I’ll say voice of the customer, if you will, with product teams or other customers as well. We have, again, a dual role here, keep the lights running, also provide some feedback and some customer perspective when it comes to the technologies that we deploy in our environment. To that point, this is a 10,000 foot view of the things that my team handles.
Customer-1 Solutions Group Portfolio
Just to give you some perspective, we have a lot of things in our hands. It wasn’t that long ago that the only thing that we cared about was ONTAP. ONTAP is still certainly the biggest chunk of our infrastructure, but now we have so many other things that we need to care about. It’s not just NetApp technology. It’s things around that technology. We certainly have our staples like ONTAP, StorageGRID, HCI, et cetera, but we also now have a lot of tools that are branded that we have to take care of and deploy and manage as well as a lot of I’ll say self-initiatives and programs that we have been building up of which we’re going to talk about and mention today.
A lot of programs that we’re building up to get our arms around was going on with the infrastructure. That leads to the consumption of new technologies, developing technologies as well as the … Which is tricky for I’ll say my team and all those that have been doing the one job for a long time, leads to the need to learn some additional what I’m going to call ancillary expertise, which is all these other technologies that touch upon the storage infrastructure. Some of these are very common these days across all the technology landscapes that you guys work with.
As we evolve as a team and we have more things to manage, we have a lot of I’ll say balls in the air that we have to juggle, so we have a large portfolio of technology that we manage. This is important to consider when we’re talking about why automation is important and why we necessitate some sort of transformation or a new view as we move forward.
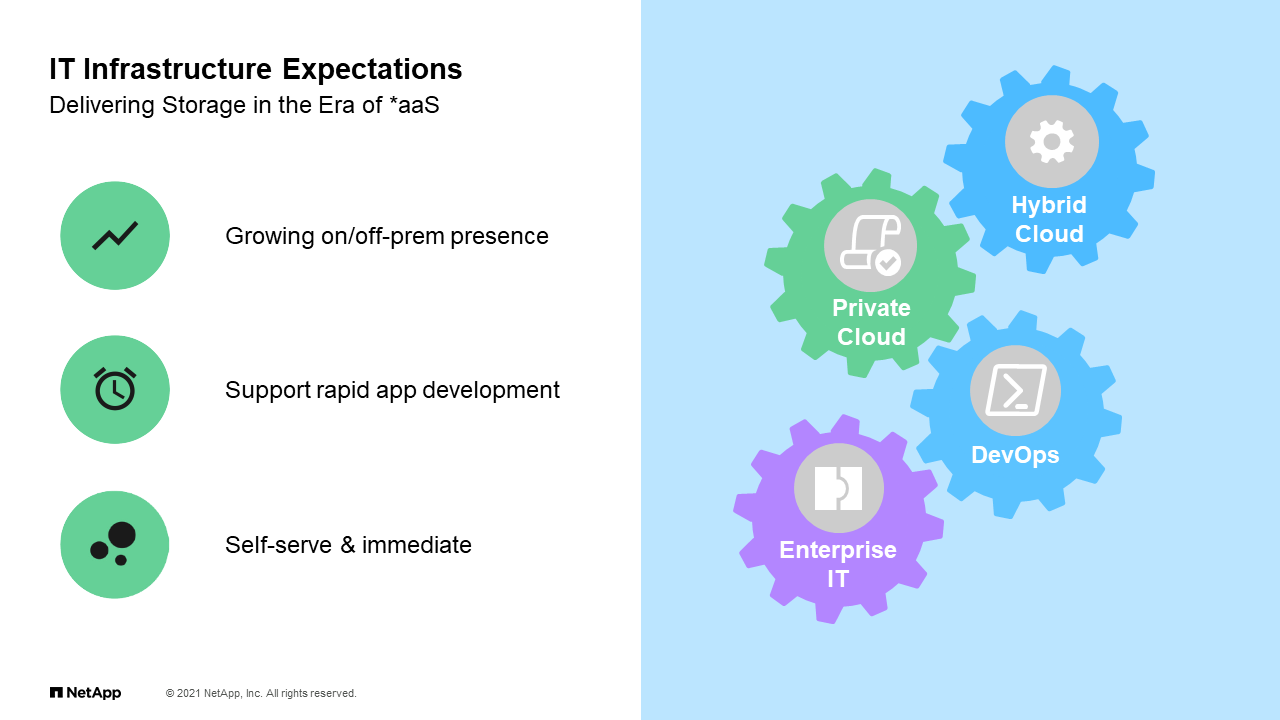
IT Infrastructure Expectations
Now, with that in mind, here’s the reality. In an IT infrastructure, the expectation from the consumers, and I’ll define consumers today as those that are coming to us the infrastructure team asking for resources of some kind, VMs, applications, et cetera, is that everything is delivered as a service. At the same time that we are delivering things as a service, they want it to be either on-prem, off-prem. It’s repeating that experience that you may have when you’re just consuming things over your phone. We have this need for things to be immediately available, so rapid application deployment that is self-service, that is there when they need it. Again, location doesn’t matter. We put all these things together, we have from an infrastructure perspective we have things like what we call hybrid cloud, private cloud, which is nothing more than deploying resources on-prem and off-prem and how we made them all work together.
We have practices or I’ll say administrative practices like DevOps which I won’t get a lot into today, but it’s a big buzzword these days. It’s about the ability to develop and operate these environments on an ongoing basis, and of course all the enterprise IT components that we bring forth as I’ll say an older enterprise organization to have the data centers to manage. At the end, the expectation today is that storage, particularly storage along with compute and network and whatnot, is delivered as a service, whether that is infrastructure as a service, platform as a service, container as a service. Those different consumables from the end users include some aspect of storage and just comes with it.
You think about that for a second. That’s a big difference from what we have done or what traditional enterprise storage managers have faced 15, 10 years ago, even five years ago for that matter. We were used to have the storage team that creates volumes, hands it over to some DBA, et cetera, et cetera, so it’s a slower process, more controlled. There’s always a need to have control and visibility, but that also slows things down. Now, that is at odds with what’s being requested or what’s being expected from us. Considering that, what is the impact on the storage infrastructure?
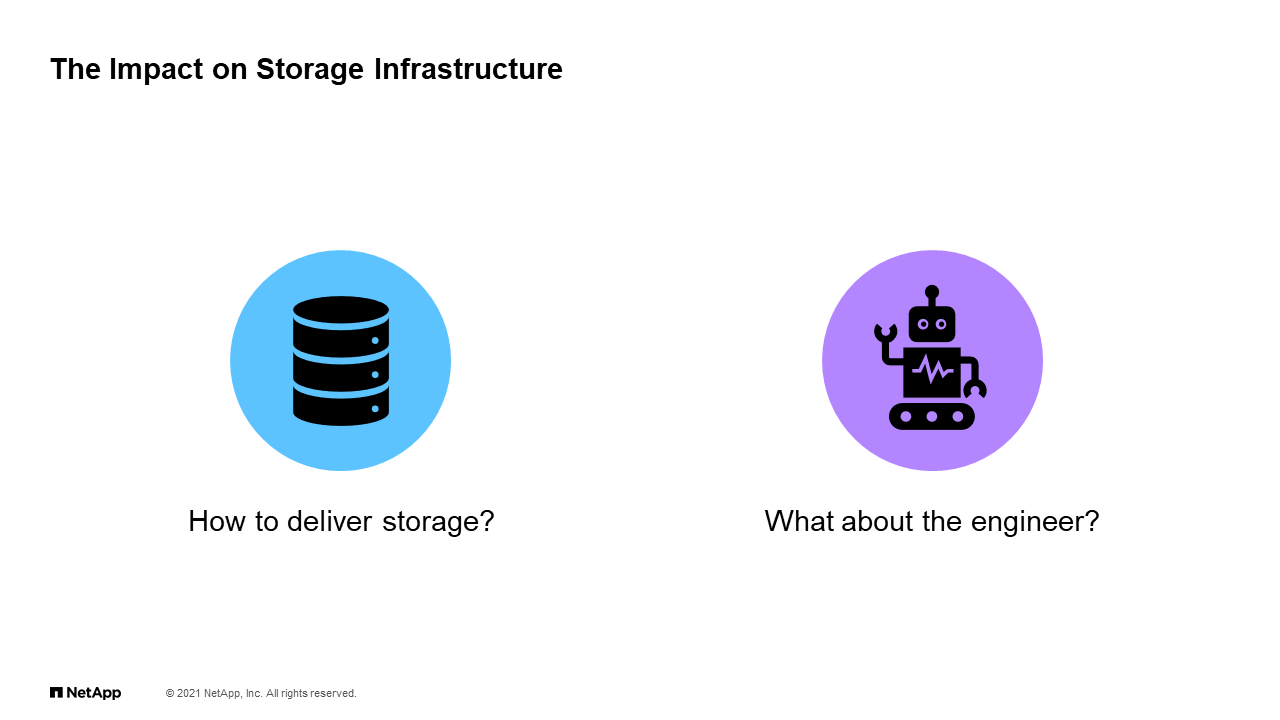
The Impact on Storage Infrastructure
The first thing is that we need to rethink how we are delivering storage. Again, that hand-holding and that hand delivery of those resources is not really meeting the need. We need to go and think about how are we going to change that, how are we going to improve that to meet this new demand. Number two is that the engineer itself probably finds themselves in a pickle where they’re not really feeling equipped to work with this new reality. It’s something that we can work with. It’s just something to recognize upfront. We have to understand how to deliver storage differently, and we need to understand how to evolve our engineers to work within this new reality.
Recognizing Changes in Enterprise Storage
The reality here is that there are changes in the enterprise storage. We have to serve a new consumer type. I mentioned a few minutes ago the fact that we have DBAs and others that have worked in the past, and they’re still there, but this new consumer type which we’ll talk about in a second is that user or perhaps that platform that is automating and consuming storage on demand and on a self-service manner. On the other side is that we as engineers had to adopt these new skills. Think about that in the context of your customers who you work with. As we have new products that we’re putting out there, we’re trying to empower the application teams directly.
As you talk to your customers out there, just imagine that we’re deploying technologies that are empowering the applications to self-serve and to some degree bypass some of these traditional storage admins. The reality is that the storage admins do have a very real role to play. They just have to grow their skillset and to be able to talk at the level of these new application developers and consumers of our technology. We’ll talk about that too.
The New Storage Consumer
Talking about the new consumer, what do we mean there? What I mean by that, and this is again our NetApp IT infrastructure, and I talked a little about this in last slides, is that we are in a position where the demand really is coming in a self-service simplified experience if you will for the end user. Just defining that a little bit better, what I mean by self-service is that they want to consume storage services either through a user portal, something like perhaps ServiceNow or something that they might have developed themselves, or something that is not necessarily logging onto the filer and creating your volume, it’s logging onto some service portal that has a catalog item that you can access and just ask for a simple request. Also, through an API interface, something that I can program against and just create things as needed. That’s what we mean by self-service.
At the same time, while the storage infrastructure underneath is not necessarily any simpler. We still have to manage all the things that we manage every day and think about performance, the capacity and different types of hardware. The end consumer wants less and less to do with those choices, at least even if they don’t recognize it. I think they do because what they want is simplicity. They want to be able to say, “I just want a file, I just want an object. I just want it to work. I want to get this much of that, and I want it to work at this performance tier.”
This is a conversation that has been happening now for years. Trying to simplify not necessarily the storage device itself, although there’s some of that too, but it’s really simplify the choices to the user. It’s something that is part of this collective system of developing services as a service. From an administrative perspective, at the same time we’re doing these things we’re not really wanting to provide the right access to the infrastructure, meaning that particular users, again it’s not logging onto a file and to grab their own volumes, but they’re doing so through some automated platform or some orchestrator. That means that they’re either logging to Service-Now or they’re deploying applications through Kubernetes, or perhaps even OpenStack or some other orchestrator that is on behalf of that user talking to the underlying infrastructure and creating all these volumes and systems or whatnot automatically.
For the most part, the infrastructure team on these tasks is hands-off, meaning that in the creation of new volumes, specifically on ONTAP, you wouldn’t be doing it by hand. You’re hands-off and you allow the automation to work its magic. You still have other things to consider, but you’re trying to relieve the storage administrator from some of these more remedial tasks and have them worry more about the bigger picture. What does that bigger picture look like? Let me show you an example.
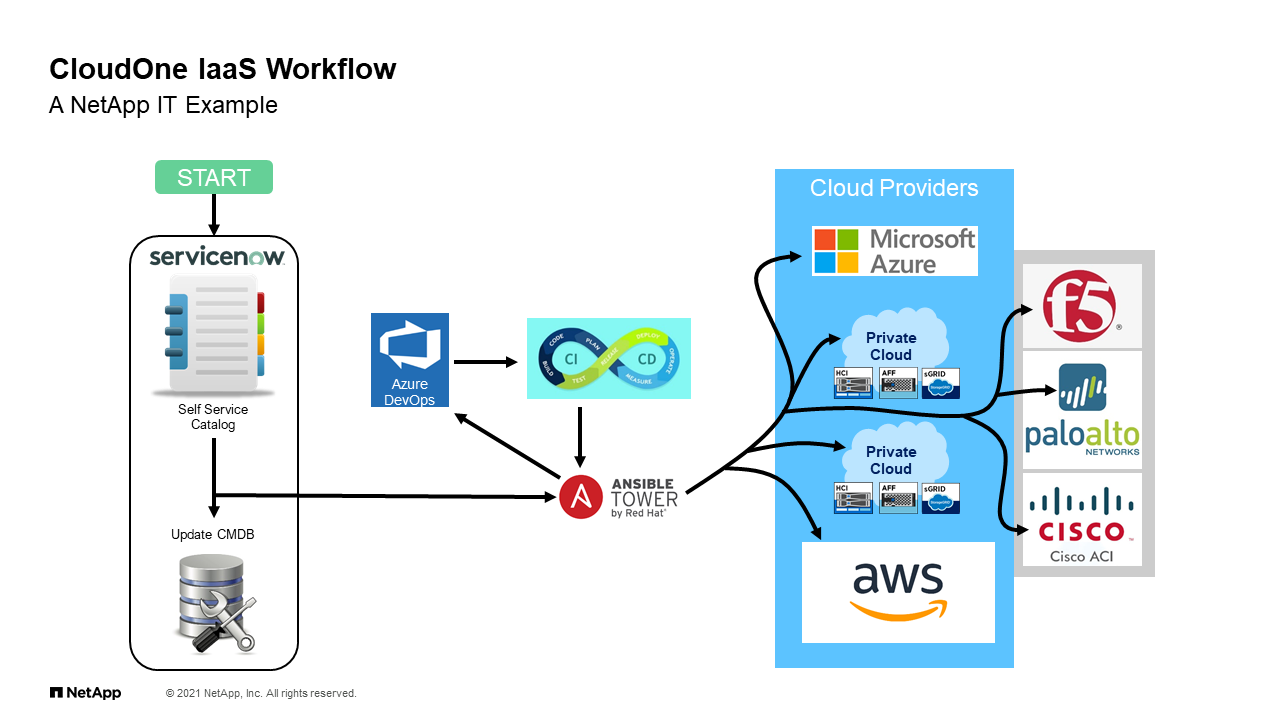
CloudOne IaaS Workflow
From a NetApp IT perspective, what does that bigger picture look like? It looks something like this. This is obviously simplified, but I’ll try to walk you through it because it’s important to understand how are we approaching this. When I talk about the self-service portal, and in our case we’re talking about Service-Now because that’s what we use at NetApp IT. It doesn’t have to be that, but that’s what we use. As a user, you can go in and create a request through a pre-determined service catalog that updates a CMDB as you go through that, and then the magic starts to happen. A call is made in this case to our Ansible tower infrastructure under which is a lot of Ansible playbooks that deploy not only storage, but many other components of the environment.
As it does all these things behind the scenes, it created either VMs and HCI, it creates volumes on IFF or buckets and StorageGRID It does all these things behind the scenes without the user really understanding what’s happening, but then at the end delivering back the user, “Hey, here’s your stack. Here’s your bucket. Here’s your VM. Here’s the stuff that you requested.” You don’t need to worry about the complexity. Now, in this execution, again, the administrator in this point of time is hands-off. The work was done beforehand building the infrastructure, building the automation that makes it happen, but the creation of that kind of stuff is already I’ll say defined through the automation and safeguarded and controlled that way.
Again, we are delivering simple solutions from a I’ll say somewhat complicated environment because it has to be to provide all the services to a mostly hands-off approach. That’s what we’re talking about when I say that we need to look at the new consumer, the way that the platform is a consumer storage, and where do we fit within that construct.
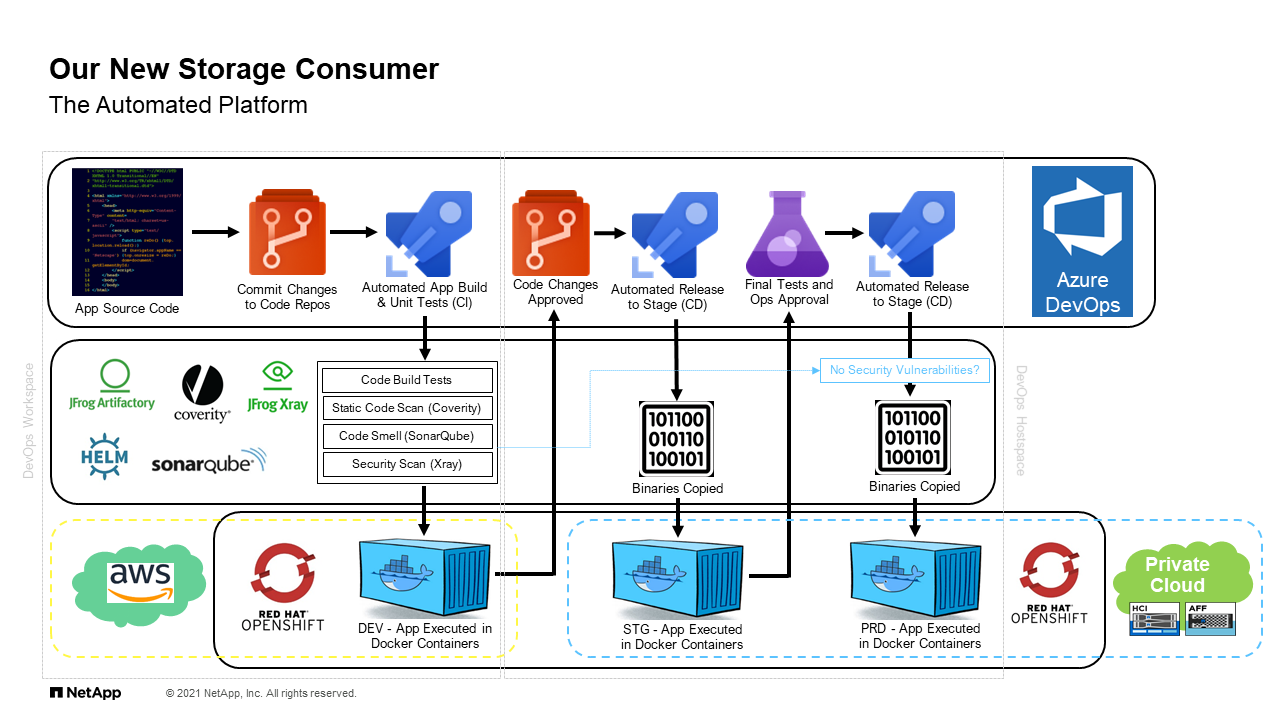
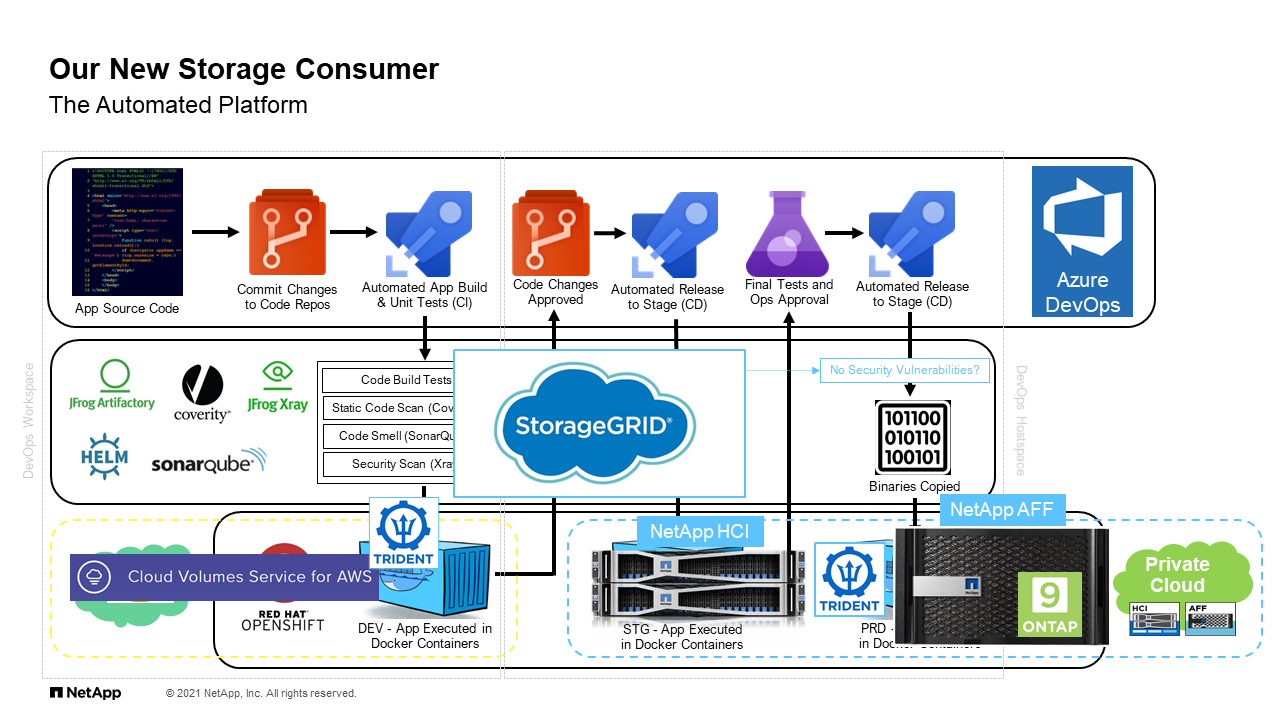
Our New Storage Consumer
Now, to I guess elaborate on that point, I want to take a deeper look into this new consumer. When we look at the storage or the automated platform, it looks something like this. I’m not going to go through the whole thing because it’s a lot, but I’ll explain briefly what we’re looking at. This is a depiction of our NetApp IT what we call CloudOne DevOps as a service solution. It’s really a way for a developer to request a development environment that is comprised of containers that have a life in AWS, and they also may have a life on-prem depending on how we deploy. If you follow the arrows, you see that it goes everything from creating the source codes, committing into some certain tools, going through some analysis, creating containers, evaluating changes, and eventually going to production. That production in this case ends up being in our on-prem systems.
When you look at this picture, it looks very broad and to some degree complicated. It’s hard to see. Where’s the storage? What is the role that we’re playing here as an enterprise storage team? The reality is it’s all throughout. There’s pieces of it all throughout this picture. This is where again we talk about the evolution of management and where automation really comes into play. We have cloud volume service in AWS, in this case perhaps even CBO in the future, we have the administration in creation and attachment on these storage volumes through Trident which is automatic and pre-configured. We have Ansible playbooks creating stuff in StorageGRID, Ansible playbooks creating VMs in HCI, and again going back to on-prem, creating more volumes through our Trident implementation on-prem.
The solutions stack here from NetApp is not necessary to the end all, be all. It’s really an engine that powers the rest of this pipeline. You can see hopefully how this is … It starts to become perhaps a little more complicated, difficult to absorb if you’re a more traditional storage administration team. This is where I think some of the rub happens. We need to understand how to service and how to look at this environment. That leads straight to the need for automation.
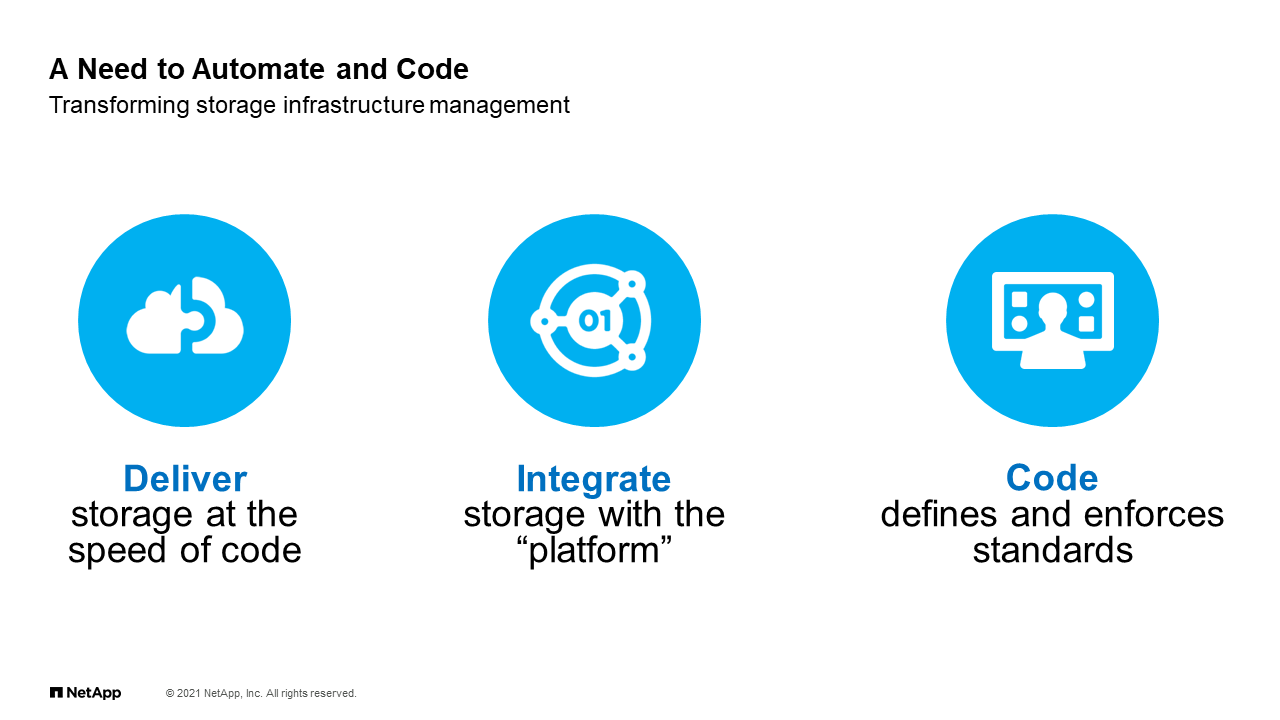
A Need to Automate and Code
What I presented so far is that it leads to some of these three pillars I’ll say. We have to deliver the storage at the speed of code. What I mean by that is again, that we can be doing handheld creation of volumes, et cetera, and this is a skill that has to be developed. We need to integrate with the existing platforms, and integration means I’m going to be able to create volumes or objects or whatever at the storage layer through automation that is called by something like Service-Now or through Kubernetes or some other orchestrator.
Finally, it also means, and this especially is important for us at NetApp IT, is as we move forward, we don’t want to continue to rely on standards, especially on the storage side, that are written on a document somewhere. That still exists to some degree, but we don’t want to have a whole bunch of documented standards that somebody has to manually read and apply. We want to be able to define those standards through code, meaning that in the same automation that we’re creating to create objects, we’re also creating automation that enforces certain parameters and standards so to speak.
To give you a quick example, when you look to deploy an SVM for instance, there’s a lot of different options you can set and whatnot. Let’s say that you care about the Volume Recovery Queue, or VRQ, one option within the SEM that allows you to recover volumes after deletion. That has a setting of how many hours you want a volume to exist before it’s permanently deleted. Well, we had a standard, and that standard was setting code through an Ansible playbook. As soon as we turned it on, it sets it up across the entire environment. If we ever had to change a standard, we just go change it in code, and next time that it executes the playbook, it just applies the new standard.
Just like that, we intend to continue to log and catalog all of our standards into the code that has maintained the environment, and therefore not having to create Wiki pages and whatnot that nobody reads. When you put all these things together, we really have the need to do delivery through code, integration through code and standards through code. You can see how now automation becomes a central part of the storage administrator’s skillset or need.
The New Storage Engineer
As we talk about the storage engineer itself, we have a little bit of a conundrum. Perhaps a little bit of a fear from a lot of storage administrators, especially those who’ve been around for a while. It’s like how do I do this? Does this mean everything I know is useless? I’m not doing storage anymore? That’s not true. The reality is the storage skills are still very much needed. I’ll say that I am vehemently against this idea that there’s an IT generalist can do everything. I think that’s a fallacy. I think you still have a whole bunch of specialists that just add more knowledge to the repertoire. You still need somebody that understands how to deploy and manage and configure storage devices, but then that person also needs to elevate those skills and augment because of this new reality.
We need not only to know the storage that we deploy, but we need a complete stack knowledge. That’s not to say that you have to be an expert let’s say in Kubernetes, but you need to know enough about it to understand, “where does the storage plug in and how does it plug in,” the same way that 10, 15 years ago, storage administrators were very close to Oracle DBAs. They understood the database very well because that was the primary customer. Today, we need to understand these automation stacks better, so we are able to care to them and build for them. We need to really talk and walk in code.
Again, this is not meaning that we have to be application developers building complex Java applications or whatever for all the code you may be using. It just means that we need to be able to do simple things through code and more advanced things as best as we can through code. It means that we have to pick up a few skills. Maybe we do have to learn a little more Ansible, a little more Python and other codes. With that, it’s not just knowing how to create the code, but it’s how to organize and make it useful and act a little bit like a development team. Again, with the focus of really infrastructure management. There’s a lot of expectations for an engineer, but again, it’s something that through a directed approach, an organized approach, we at NetApp IT have been able to attain. Again, it’s always a work in progress. I’ll show you what that looks like. It’s a reality that we have to accept and go through.
Question: Is this service available through channel or only direct? As far as I see, it is the consumer goes directly to the platform. What does the channel contribute in this?
Eduardo: Okay. I think what the partners need to remember is we’re trying to empower the customer. When we look about the NetApp technology, I represent NetApp, so we want to sell NetApp device and NetApp technology and partners resell them. As partners, you’re also reselling a lot of our technologies, and I think I presume that some of your customers may be trying to figure out how to put it all together and deliver solutions internal to the customer. The customer is trying to build their own internal solutions for whoever is consuming their resources. The consumers are not people on the internet. The consumers are the application team. That’s the infrastructure team.
I think as partners, the importance here is to really try to help our customers get to the point where they are comfortable with various technologies integration points and be able to deliver these solutions internally. That’s not to say … I don’t know everybody’s background here. Maybe somebody here is doing a hosted services or something of the like. If you are, then you will be the person building this stuff in your environment to service your own external customers. Hopefully, that answers the question. I’ll be happy to elaborate.
Building New Skills
Let’s think about in the context we just talked about, about the administrator and the role of the partners here, there is actually I’ll say a lot of opportunity here for education, perhaps even additional services and whatnot that you can do with your different customers to really help them build these additional skills. I think that not only will they be individually encouraged by learning new stuff, but they will actually be much more successful and therefore hopefully much more rewarding to the partner in the sense of future business and future collaboration because we’re trying to help the customer understand this transition, not fear it, but embrace it and go ahead and get to the next level, which again is not just technology, it’s also knowledge, but the more knowledge and more probably technology they end up consuming in the long run.
When it comes down to the administrator, what do we look at? We need to identify skills or the customers need to identify skills that are outside of just storage. I think that’s obvious at this point. We need to understand the related infrastructure. If you’re a partner that are delivering other components of the ecosystem, this is a great opportunity to go and talk about, “Hey, let me talk to you about how this integrates with X, Y, Z, that is also part of the catalog that we bring to customers.” We want to encourage customers to have cross-functional work. This is easier said than done. I’m willing to bet that if you talk to the larger the organization, the more stylish and perhaps older organizations have the toughest time with this.
We have a lot of silos, and when you go talk to a storage manager, they have no clue what the … Maybe they have a separate automation team, maybe they have a separate server team, separate application team. They’re all big silos. That creates problems, not just for you in terms of interacting with the customer as a potential deal in the future because you’re trying to sell things that perhaps one silo doesn’t understand versus the other, but it creates a problem for them too, and for us internal to IT the problem is that we need to be able to understand, again thinking about the complete stack, what are our neighbors in the infrastructure doing so we can be at the same level and then build solutions that integrate together.
Of course, there’s a lot of new technology at NetApp, and I can rattle off some of them. We have a new API solution in ONTAP itself. We have all the things that are going through Cloud Manager like CVO. We have Cloud Compliance, Cloud Secure, all these things can play a role in this bigger ecosystem. It’s a matter of understanding how they’re stitched together and how do they work together to deliver what you want. The answer is not going to be most likely copy and paste for everyone. It’s going to be specific to what the situation is at hand. As managers, you talk to the managers of the infrastructure teams. Again, they also need encouragement and I think support to understand the importance of building this ancillary skillset to help the engineers move forward and their teams move forward.
When we look at I’ll say the skillset that we have been building within my team, again to give you some perspective, I don’t want to say the most junior person in my team has probably been doing storage for at least nine, 10 years. They’re all traditional storage administrators.
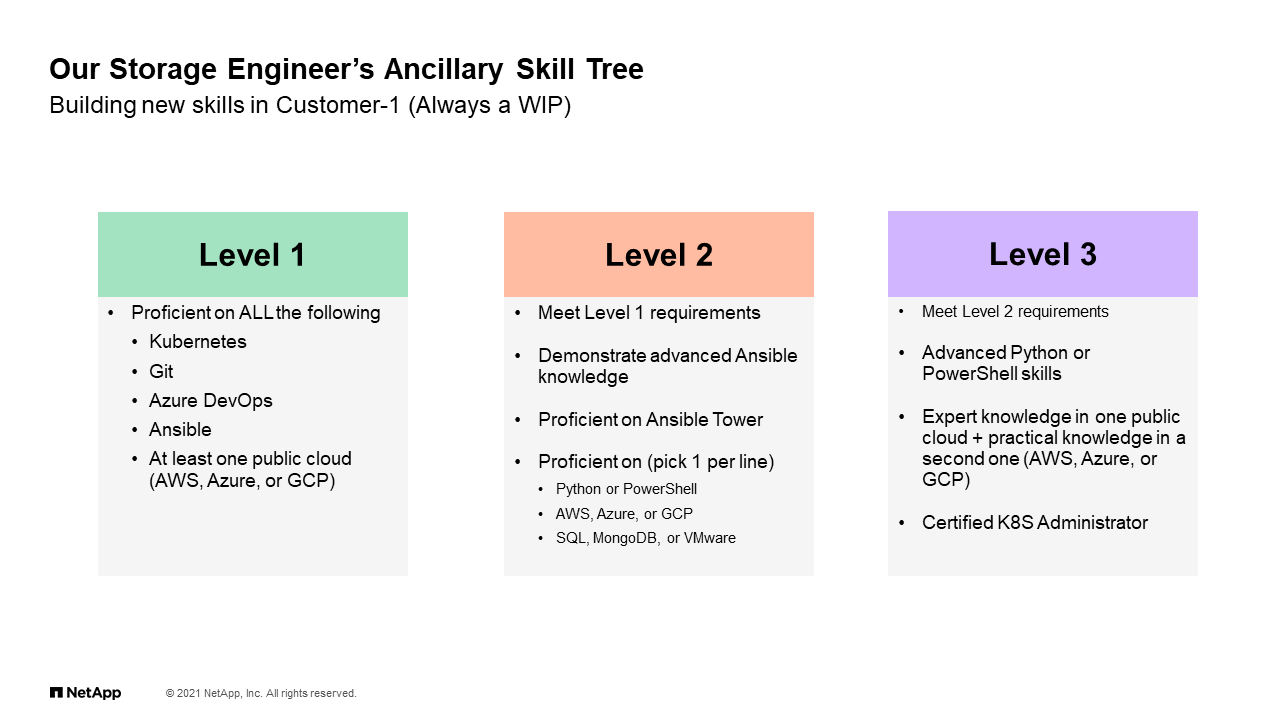
Our Storage Engineer’s Ancillary Skill Tree
This is again hard for us. We have been working on building an “always a work in progress” type of skillset tree where we’re trying to branch out. These technologies, a lot of them are just open source, but they also touch upon solutions again that you may be trying to position at your customers. Without the knowledge, I think they will be unsuccessful. When we are thinking as a team to build our own technology and our own technology knowledge I’ll say, this is what we’ve come up with so far.
I’m not going to go through the whole list, but you can see I tried to build some sort of progressive skill tree where we are really tackling automation first by learning simple things like Git, Azure DevOps is another tool that we use to do a lot of the management of code, Ansible which is front and center today, and if you’re not aware, there’s extensive Ansible modules for everything, ONTAP, we even have modules for StorageGRID and SolidFire. A lot of automation going through that these days. Of course, a lot of learning in the public cloud across all different hyperscalers. What we’re trying to do is based on that I’ll say level one, we’re trying to build on top of that and build proficiency. Again, the more we get to I’ll say the right hand of this chart, the more educated, the more skilled we are at tackling automation problems and automation solutions as we move forward.
It’s always a work in progress. Now, considering that we talked a little bit about the new consumer, we talked a little bit about the new skillset. At this point, we’re really going to talk about recognizing what customers probably are going through and what they need to think through as they’re trying to evolve their practices, and now maybe you’re in a position where you can talk about automation because I think the mistake that we do or lot of customers do, we did that as well, it’s try to put the cart before the horse. Let’s talk about deploying scripts. Before you do that, you have to go through some understanding on why are we doing this and where are we heading. That’s hopefully what we’ve just done.
Building a Storage Automation
With that in mind, let’s talk a little bit about the automation program that we built in Customer-1.
Like every program, it starts to take a big statement. Again, from a traditional enterprise management perspective we’re moving to a place where we are aiming to have a program that drives a perpetual effort to define all storage infrastructure deployment, configuration and operational tasks via code, which is what I said a few slides ago. We’re really trying to move towards this goal, and this is a never-ending goal. We will continue to iterate and reiterate to build that pipeline in the administration.
Automation Program Objectives
Now, when you look at the components, this is how we defined it. I think this is again where customers can certainly use some help from their partners to try to organize their thoughts, and in between there’s certainly consultation, there’s probably products and whatnot, but this really comes down to organizing your thoughts about how you’re going to tackle as the infrastructure team the automation of your infrastructure. We define scope, in this case we’re talking about automating infrastructure. We started with ONTAP, so we’re defining things within the ONTAP ecosystem. We’re identifying platform, tools and processes which are … I’ll give you an example in a second, but it’s really about what tools do we need to learn like Git or Ansible or whatnot to be able to be successful.
Then, developments on processes about how do we take an idea of something that we want to do to something that is actually created and maintained. Of course, we talked about the skill gap. We identified a skill gap for the engineers. Not everybody is on the same page, but we are trying to guide them through that and try to keep them educated and interested. Of course, ultimately it’s operationalize which is putting it all together and making it work on our recurrent basis.
Components of Automation Program
We’ll look at the components a little bit deeper. That’s about tools and whatnot. Here are the things that we thought about. First and foremost, we thought about where do we store our code, where do we store the things that we create? Examples of that would be Git. We use a lot of Azure DevOps which has a Git repository within it. We also think about well, okay, a development platform. Do we develop in Perl, PowerShell, et cetera? The answer is that it doesn’t really matter. You just have to feel where your skillset is and what is most appropriate for the job, and go down that path. There’s no real restrictions, but there’s some thought that needs to be put in there based on the skillset and what you want to accomplish.
And then, also more advanced topics in the journey of automation for us was orchestration and deployment. We create the code, we upload it to the Git repository. How do we deploy it and how do we maintain it? Again, there’s different tools for it. Again, we’re using a lot of Azure DevOps to do that, but there’s other tools like Jenkins and whatnot that manage how code is deployed to the systems that need it. This is certainly not last, but it’s part of the thought process is once you created something, it has a life. It has this version 1.0 feeling that you’re going to have to go back and fix things or improve and whatnot. You have to also think as a development team how do you absorb requests for features or bugs and whatnot, and that’s another thing that we need to consider when we’re thinking about the program.
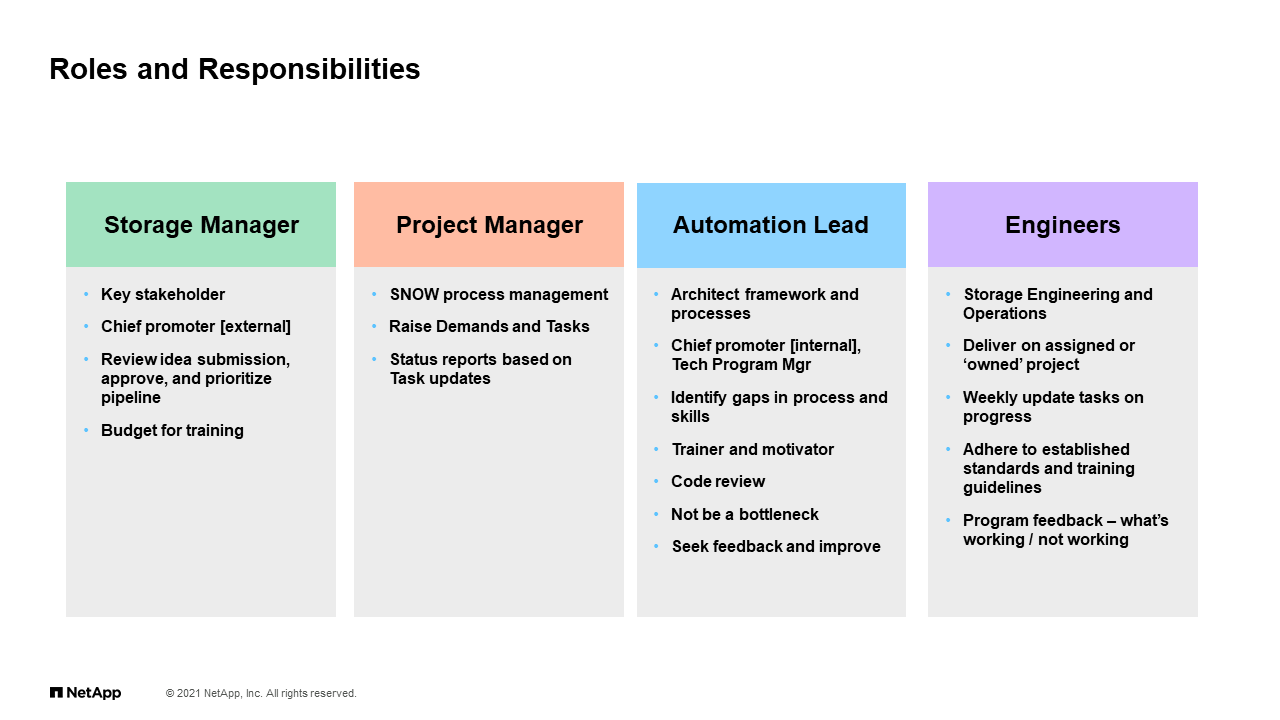
Roles and Responsibilities
When we think about the roles and responsibilities within my team, and again, think about the customers you guys interact with, you’re trying to promote, you’re trying to help them get to that automation and next step. It also requires support internally. We defined roles within our organization to try to build this program, to make this program successful. That starts with myself, the storage manager, I’m the one trying to carry the flag, talk about it, make sure that we have the right budget and whatnot. We have project managers who are involved helping our engineers organize their work.
We have within the team identified what I’m going to call an automation lead, a person that is more versed than the others in coding and serves as a mentor and a helper in defining standards and gaps and doing some code review, but at the same time not be a bottleneck, not be in the way, just help move things along. Of course, at the end it’s all the engineers. The engineers, as I mentioned, they have different levels of skill, and we have to support and provide them the resources and as managerial support to spend time on doing this thing and going and creating all these solutions.
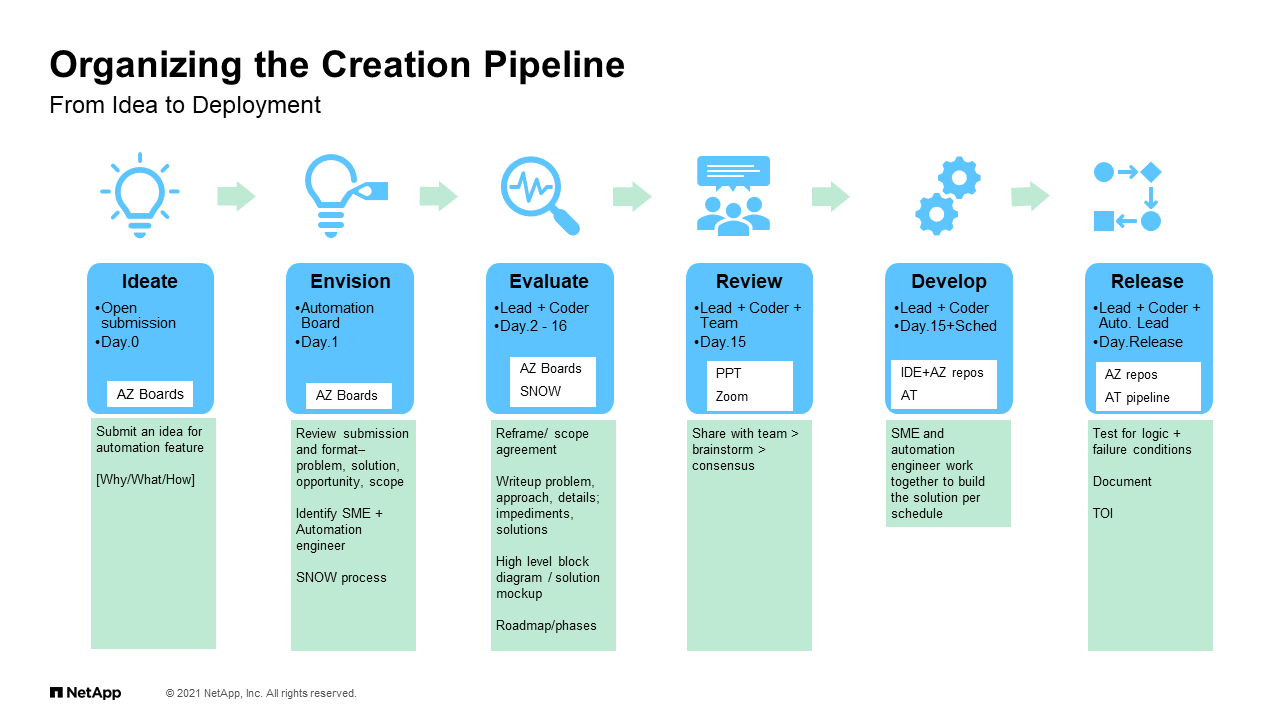
Organizing the Creation Pipeline
When you look at the operationalization, a big part of it is creating this pipeline. This pipeline which actually comes out of this, how we do it today, we have created a process under which we try to formalize the generation of ideas, we discuss it through an envisioning process which is really more a review, evaluate the feasibility. It’s reviewed with the lead, and then there’s development time that happens, and there’s a release. Before something is released, there’s standards around, “Yeah. You should have some documentation. You should have some … We call it TOIs, transfer of information. You should have a short presentation of what it’s doing, so make sure that people understand. The release is not the end of the line. The release is the end of that particular version.
I mentioned earlier that we have to have a way for us to address bugs and address future requests and whatnot. This pipeline as we create it, it helps us organize our thoughts, but also organize the ongoing maintenance of anything that we create. Again, this is really about trying to teach our infrastructure team to be more of a development team not taking away the infrastructure part, but just adding to it some new skills.
Road to Infrastructure Automation
As lessons learned, as we look at what we did and some of the things that we talked about, if I summarize some of the stuff that we just covered, as we build our infrastructure program, this are the things that maybe are of interest to your customers. Putting it very plainly, the first thing that we have to deal with is learning how to speak the language. We have mentioned things like Git, Ansible, Kubernetes, et cetera. I’m sure a lot of you are very well versed with what those things are, but not everybody is. We weren’t. We really have to spend some time learning what do these things even mean, how are they put together, how do they work before we can even learn how to actually use them.
We spent some time early on trying to define what’s what and how are those other teams leveraging these technologies. And then, the next big step which we talked about a little bit was really defining this repository where we create code and we save code. The reality is that throughout time, people have always written scripts. There’s somebody’s laptop and some shared drive or whatnot. That’s not really that good for today’s demands. We can’t build consistent infrastructure automation with somebody’s home directory scripts. We have to have a versioning control, a single source of truth where things are sitting.
And then of course, as we venture into creating the tools and the automation, we try to focus on small and medium needs. Let’s start small. Let’s build solutions that we need based on what we have in our hands, meaning that it’s very easy to get boggled down by boiling the ocean, saying, “I want to automate everything. I want to automate everything we do,” which we do, but if you start with that premise, you’re probably not going to get anywhere. You have to say, “Hey, I want to automate the creation of an SVM. That’s all I want to do right now because that’s important to us, and that’s something that we do often.” Scope small and start small, and then you iterate from there.
Of course, as we just discussed, we have to build a pipeline. As we create all these pieces of code, there needs to be a way to organize the effort and to iterate through this effort. Again, it’s okay to create what we’re going to call a version 1.0, or sometimes we call it MVP, minimum viable product. It’s okay to create something small that does something very directed and it’s not super robust. That’s okay because we’re going to iterate over time. The idea is that these things have a life of their own. It’s an ongoing journey to go through this. I believe that many of your customers are probably going through a similar evolution. Again, for us it’s been big lessons learned. It’s not something that is done overnight. It’s something that we’ve done over the past I’ll say at this point two, two and a half years to get to where we are today.
Up Next for Customer-1
From a team perspective, where do we go from here? We have a program, we have identified skills, we have identified where do we want to go with this. We still have a big chunk of what we’re going to call traditional infrastructure that we do manage, but as we move forward a lot of the new deployments, a lot of the new applications are being built with that new as a service model. As we move forward, we’re going to continue to deliver more as a service experiences, more catalog items through things like Service-Now, more integration with Ansible, Python, et cetera.
We will continue to promote the automation message not just in a forum like this, it’s really more about internally. I think as you talk to your customers and work with your customers, this is a role that you guys can also play. You want to promote the message of automation because it’s going to happen anyway. Somebody who’s not looking down this road and working on this is going to be left behind. You want to be able to empower your customers to get with the program, if you will, which includes training of engineers in strategic areas, in growing that knowledge, and as team of engineers internal to us we’ll continue to grow and maintain that pipeline that we just talked about. That is always a work in progress. That is a hard thing to do, especially in a development team.
We will continue to do that, and of course as we move forward it’s an attitude of code first if you can. If there’s anything we need to do, I will say more than once, but even if it’s just once we’re probably going to try to think about doing that through code because once you have it there, you can always use it in the future and update it, and again define your standards through that code. This is again our perspective, how we see it, how we are going to move forward.
Key Takeaways
Hopefully, as you’re thinking about this, a lot of this talk is really more about an engineering team, how do they should think about their own automation strategy, but I think as partners that work directly with customers, I think it’s important to recognize that the landscape and expectations of those IT teams has changed. There will still be some need for traditional, but there’s a lot of need whether by force or natural growth to have this automated consumer that we talked about that need to recognize that these consumers have changed and are evolving and are part of an automated platform. That’s an important thing to recognize and to bring to the table when we’re talking to customers. Because of that, it’s important that those teams that you’re working with are embracing an infrastructure as code mentality.
Again, there’s a lot of opportunity there, not just for NetApp technology to be placed in those conversations, but other things that are complementary and are helping them build these solutions. If you have any opportunities to provide assistance through either training or I’ll say even staff augmentation to help them build solutions, that’s also something that’s very much needed. We’ve gone through that and we went through a lot of training, we even had third parties at NetApp IT helping us build some of the initial automated solutions. I think there’s a lot of value here not just talking to a direct customer or manager of storage, but also to somebody who works with those groups to help them bring more value within the infrastructure and really at the end strengthening the partnerships that we made with those customers.
With that, I’m at the end of the presentation. We still have about 10 minutes left. If there are any questions or any conversations that we’re going to have, I’m happy to talk about it.
Thank you for reading. Email netappit@netapp.com with any questions.